Réseaux de neurones¶
Principes¶
Un réseau de neurones artificiels est une méthode de classification par apprentissage s'inspirant du fonctionnement du cerveau humain.
Le concept des réseaux de neurones artificiels fut inventé en 1943 par le neurophysicien Warren McCullough et le mathématicien Walter Pitts. Dans un article publié dans le journal Brain Theory, les deux chercheurs présentent leur théorie selon laquelle l’activation de neurones est l’unité de base de l’activité cérébrale. C'est en 1957 que le Perceptron, le premier réseau dédié des tâches de reconnaissance de patterns complexes, est présenté. Faute de puissance de calcul, ces approches sont mises en sommeil et réapparaitront en force en 2010 boostées par l'essor technologique des calculateur, notamment de la puissance des cartes graphiques développées pour les jeux vidéo.
Modèle¶
La détection d'objets dans des images n'est pas un problème récent : les modèles utilisés aujourd'hui .........;;;; Pour bien comprendre de quoi il retourne, il est nécessaire de parler de l'évolution des réseaux dans la dernière décennie.
AlexNet (2012)¶
On ne peut pas parler de Deep Learning sans mentionner AlexNet. C’est en effet le pionnier des réseaux de neurones dédié à la classification des images. Développé par Alex Krizhevsky, Ilya Sutskever et Geoffrey Hinton, il est le premier réseau de neurones à remporter (haut la main) en 2012 le Challenge ILSVRC de la classification des images. Aujourd’hui, et depuis lors, les algorithmes évalués reposent presque tous sur des réseaux de neurones. AlexNet a eu un impact énorme sur le domaine et la plupart des réseaux suivants étaient plus ou moins basés sur son architecture.
AlexNet est composé de 5 couches convolutionnelles, suivies de deux couches entièrement connectées (permettant d'effectuer la classification à proprement parler), puis d’une couche finale softmax (permettant d'attribuer aux objets détectés les probabilités d'appartenance aux différentes classes).
L’idée de ce réseau dédié à la classification d'images couleur de 227x227 pixels est la suivante : chaque couche convolutionnelle apprend une représentation plus détaillée des images que la précédente ; la première couche est capable de reconnaître des formes très simples, la dernière des formes complexes telles que des visages. L'enchainement des couches de convolutions permet de réduire drastiquement l'information à analyser en passant progressivement d'un vecteur de 227x227x3 coordonnées à un vecteur signature de 4096 coordonnées. Les deux couches entièrement connectées et le softmax jouent le rôle d'un classifieur classique de type Random Forests ou SVM (Support Vector Machine).
ZFNet¶
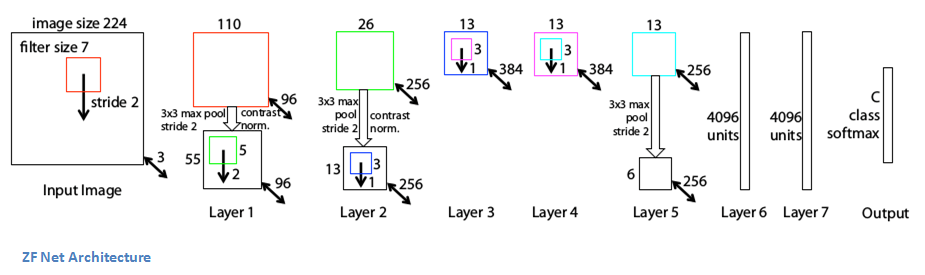
Alexnet est un réseau très important duquel découleront les réseaux de référence ZFNet et VGG. ZFNet a la même architecture globale qu’AlexNet, c’est-à-dire 5 couches convolutionnelles, deux couches entièrement connectées et une couche softmax de sortie. Les différences reposent sur l'utilisation de noyaux convolutionnels mieux dimensionnés.
VGG¶

VGG est un réseau très profond et simple. Dans la version la plus courante, il comporte 16 couches (les couches bleues de mise en commun ne sont pas comptées sur le schéma). Cependant, l’architecture globale est très similaire à celle d’AlexNet. En fait, les couches convolutionnelles d’AlexNet sont ici représentées par deux ou trois couches convolutionnelles successives. Chaque couche convolutionnelle a un noyau 3×3 contrairement aux autres réseaux qui ont des noyaux de taille différente pour chaque couche. Les couches convolutionnelles représentent de ce fait l’image d’une manière beaucoup plus efficace pour la classification. Par de réels changements pour les deux couches entièrement connectées et le softmax.
Ces réseaux importants sont construits pour classifier les images, c’est-à-dire pour donner la classe à laquelle appartient l'image. Ce problème est assez bien résolu puisque les résultats d’aujourd’hui dépassent les performances humaines.
Mais l'enjeu principal reste la détection d’objets dans les images. Ce problème est bien plus difficile car l’algorithme doit non seulement trouver tous les objets dans une image mais aussi leur emplacement exact. En d’autres termes, l’algorithme doit être capable de détecter qu’une zone spécifique de l’image (à savoir une « boîte ») contient un certain type d’objet.
R-CNN (2013)¶
R-CNN (Region-based Convolutional Neural Network) a été le premier modèle à appliquer le deep learning à la tâche de détection d’objets dans des images. Il bat les précédents de plus de 30% par rapport au VOC2012 (Visual Object Classes Challenge) et constitue donc une amélioration considérable dans les domaines de la détection d’objets.
Comme mentionné précédemment, la détection d’objets présente deux difficultés : trouver des objets et les classer. C’est le but de R-CNN : diviser la tâche difficile de la détection d’objets en deux tâches plus faciles :- Objects Proposal (trouver des objets)
- Region Classification (les comprendre)
- ceux qui regroupent les points de l'image en super-pixels (Selective Search, CPMC, MCG, …),
- ceux qui utilisent une fenêtre glissante (EdgeBoxes, …) pour faciliter l'analyse du contenu de l'image.
R-CNN est en fait indépendant de l’algorithme d’Objects Proposal et peut utiliser n’importe laquelle de ces méthodes. Il prend en entrée les Regions Proposal (ou d’objets ou de boîtes). La plupart des algorithmes Regions Proposal produisent un grand nombre de régions (environ 2000 pour une image standard) et l’objectif de R-CNN est de trouver quelles régions sont significatives et les objets qu’elles représentent.

R-CNN donne des parties d’une image et doit les classer. Nous avons vu précédemment que la classification des images est une tâche assez facile grâce aux réseaux de deep learning tels qu’AlexNet. Le but de R-CNN est d'utiliser du deep learning pour classer chaque région d’intérêt produite par un algorithme d’Object Proposal, le postulat étant que chaque région ne contient qu'un seul objet.
R-CNN n’utilise pas directement un AlexNet sur toutes les propositions de régions car en plus de classifier une image, le modèle devrait pouvoir corriger l’emplacement d’une proposition de région si elle n’est pas correcte.
Cependant, si vous vous souvenez d’AlexNet, nous avons vu que les couches entièrement connectées après les convolutions pouvaient en fait être remplacées par n’importe quel autre classificateur. C’est exactement ce qui est fait dans R-CNN. La partie convolutionnelle d’Alexnet est utilisée pour calculer les caractéristiques de chaque région, puis les SVM utilisent ces caractéristiques pour classer les régions. L’avantage de cette méthode est que le réseau neuronal (Alexnet) est déjà formé sur un énorme ensemble de données d’images et est très puissant pour concevoir les propositions de régions. Avant cette étape de classification SVM, le réseau neuronal est affiné pour prendre en compte une nouvelle classe « fond », afin de distinguer les régions avec ou sans objets.
Les propositions de régions, qui sont des rectangles de différentes formes possibles, sont transformées en carrés de 227×227 pixels, la taille d’entrée requise par Alexnet. Elles sont ensuite traitées par le réseau et les valeurs obtenues sur la dernière carte de caractéristiques sont sorties. La région est alors devenue 4096 vecteurs d’entités. Ces vecteurs d’entités codent les informations des images d’une manière bien plus efficace pour traiter la classification.
Ensuite, une stratégie de SVM à un seul repos est appliquée sur tous les vecteurs de régions. C’est-à-dire que si le modèle est entraîné à reconnaître 100 classes, alors 100 SVM binaires seront traités sur chaque région. En conservant le meilleur score parmi tous les classificateurs binaires, nous obtenons la classe d’objet détectée correspondante (ou le fond en fait). Même si les classificateurs sont tous capables de reconnaître une seule classe parmi les autres, les résultats sont bons car les caractéristiques extraites d’Alexnet sont partagées par toutes les classes.
Il y a ensuite une étape de régression des boîtes englobantes afin de corriger la localisation des propositions de régions qui n’étaient pas bonnes, par exemple si la boîte n’est pas bien centrée sur l’objet ou pas du bon rapport. Cette phase de régression produit des facteurs de correction aux coordonnées de la boîte englobante. Pour cette tâche, des régresseurs linéaires spécifiques à la classe sont formés sur les cartes de caractéristiques pour prédire les boîtes limites de la vérité de terrain.
Finalement, il existe un mécanisme permettant de ne garder que les meilleures régions. Si une région chevauche une autre de la même classe avec plus d’un certain pourcentage (environ 30% fonctionne assez bien), seule la région la mieux notée est conservée. Cela permet de conserver un nombre assez raisonnable de régions.
C’est tout pour le R-CNN. Cet algorithme est puissant et fonctionne très bien, mais il présente plusieurs inconvénients :
Il est très long. La proposition de région prend de 0,2 à plusieurs secondes selon la méthode, puis l’extraction et la classification des caractéristiques prennent à nouveau plusieurs secondes. Elle peut aller jusqu’à une minute sur un processeur pour une image.
Ce n’est pas un algorithme fluide. Il y a trois étapes différentes qui sont presque indépendantes et qui nécessitent donc une formation séparée.
SPP-Net¶
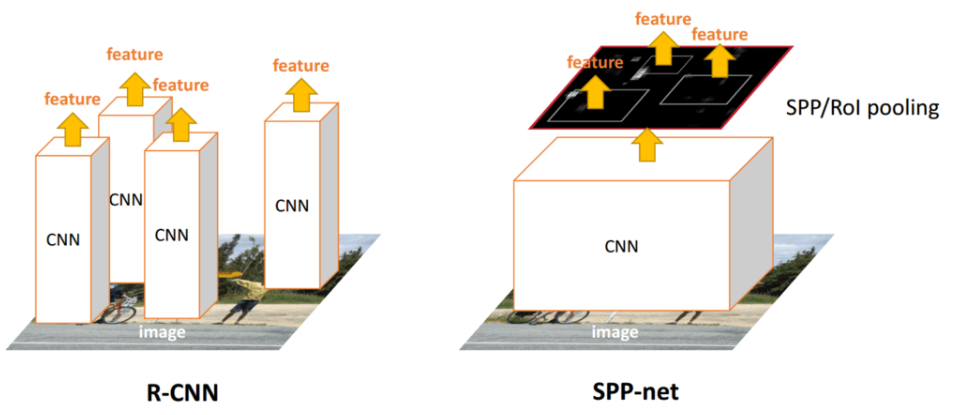
Dans le RCNN, chaque proposition de région doit être définie dans une sous-image de taille fixe de 227×227. C’est-à-dire que chaque région doit avoir la même dimension. C’est une limitation plus ou moins impactante, car il est évident que les images et les régions peuvent être de toutes tailles et de tous rapports. Il est donc nécessaire d'effectuer certaines transformations sur les images qu'elles respectent ces contraintes. Deux des transformations les plus courantes sont le recadrage de l’image (en ne sélectionnant qu’une partie de l’image de taille correcte) et la déformation de l’image (en changeant le ratio). Ces deux techniques présentent des inconvénients évidents et peuvent modifier l’image d’une manière qui diminue la précision de détection.

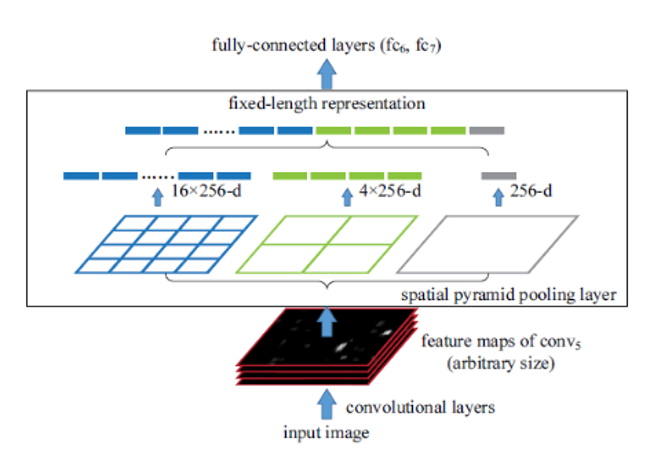
Mais contrairement aux couches entièrement connectées, les couches convolutionnelles n’ont pas réellement besoin d’une entrée de taille fixe. Ces couches se trouvent en profondeur dans le réseau, il n’y a donc aucune raison de fixer l’entrée du réseau alors que cela peut être fait juste avant les couches entièrement connectées. C’est l’objectif de SPP-NET, qui introduit un nouveau type de couche appelé Spatial Pyramid pooling, placé après les couches convolutionnelles et avant les couches entièrement connectées. Cette couche met en commun la dernière carte de caractéristiques de manière à générer des vecteurs de longueur fixe pour les couches entièrement connectées. Grâce à cette mise en commun des pyramides spatiales, il n’est pas nécessaire de déformer ou de recadrer les images saisies.
Le R-CNN prend beaucoup de temps car les caractéristiques fournies au SVM sont calculées indépendamment pour chaque proposition de région. Par exemple, si 2000 propositions de régions sont extraites, elles seront traitées une à une par un réseau (de type AlexNet) pour calculer leur carte de caractéristiques. La méthode proposée dans SPP-Net accélère drastiquement les traitements, les couches convolutionnelles n'étant calculées qu’une seule fois pour l’ensemble de l’image (et non pour chaque proposition de région). L’emplacement de chaque proposition de région est ensuite cartographié sur l’ensemble de la carte des caractéristiques de l’image et des caractéristiques à longueur fixe sont extraites de cette carte des caractéristiques avec la couche de regroupement des pyramides spatiales.
Le regroupement des pyramides spatiales repose ni plus ni moins sur l’appariement des pyramides spatiales, une méthode qui était largement utilisée dans les tâches de reconnaissance d’images avant l’émergence du deep learning. Il est capable de traiter différentes échelles, tailles et rapports d’aspect, ce qui est très important dans la détection d’objets.
Les caractéristiques de la proposition de région sont alors extraites ; une classification par SVM et un ajustement des boîtes englobantes sont effectués sur chacune d’entre elles, de la même manière que dans le R-CNN. Cependant, le processus complet est 10 à 100 fois plus rapide au moment du test et 3 fois plus rapide au moment du train.
Fast RCNN¶
L’objectif principal de Fast-RCNN est d’améliorer les deux méthodes précédentes en extrayant les caractéristiques et en effectuant une classification de bout en bout avec un seul algorithme. Il est plus facile à former, plus rapide au moment des tests (la phase de classification est presque en temps réel) et plus précis. Toutefois, cet algorithme est toujours indépendant de l’algorithme de proposition de boîte. Ainsi, les régions sont toujours proposées séparément, par un autre algorithme.
blablabla
Faster RCNN¶
Yolo¶
Erreur¶
Les différences entre les sorties du réseau et les sorties attendues caractérisent l'erreur du réseau. Cette erreur prend le plus souvent la forme d'une moyenne quadratique ou d'une entropie croisée selon les réseaux ou leurs étapes d'apprentissage (détection, localisation, classification, etc.). Cette erreur est continuellement évaluée par le réseau au fil de son apprentissage sur une partie du jeu de données annotées conservée à cette fin. Plusieurs cycles d'apprentissage sont enchaînés par le réseau pour lui permettre de diminuer significativement son erreur par application d'un mécanisme de pondération.
Pondération¶
A chaque cycle d'apprentissage, un mécanisme profond consistant à pondérer l'influence de chaque neurone des différentes couches du réseau est appliqué pour diminuer l'erreur globale du réseau : c'est la rétropropagation. On dit que les poids du réseau de neurones sont alors modifiés.
En appliquant cette étape plusieurs fois, l'erreur tend à diminuer et le réseau offre une meilleure prédiction. Il se peut toutefois qu'il ne parvienne pas à échapper à un minimum local, c'est pourquoi on ajoute en général un terme d'inertie (momentum) à la formule de la rétropropagation pour aider l'algorithme du gradient à sortir de ces minimums locaux.
Epoque¶
Ce terme caractérise UN cycle d'apprentissage du réseau, i.e. le fait que le réseau ait "vu" l'intégralité des données une et une seule fois. Dans son processus d'apprentissage, le réseau sera amené à effectuer plusieurs cycles pour minimiser au maximum son erreur.